3 practical examples of tricking Neural Networks using GA and FGSM. How can object classification be easily fooled?
 By Przemysław Przybyt
By Przemysław PrzybytTable of Content
Updated: 28.11.2022
Hi! I’m Przemysław from Northern Poland where I’m working for an Python AI Software Development Company. My interests in AI were raised while studying the topic of reinforcement learning and computer vision. I have a strong inner need to see how things are done under the hood so I wanted to check if I could mess with some well known object classification models such as CNNs (Convolutional Neural Networks). They are just a bunch of numbers and mathematical operations, so let’s see if we can play with that!
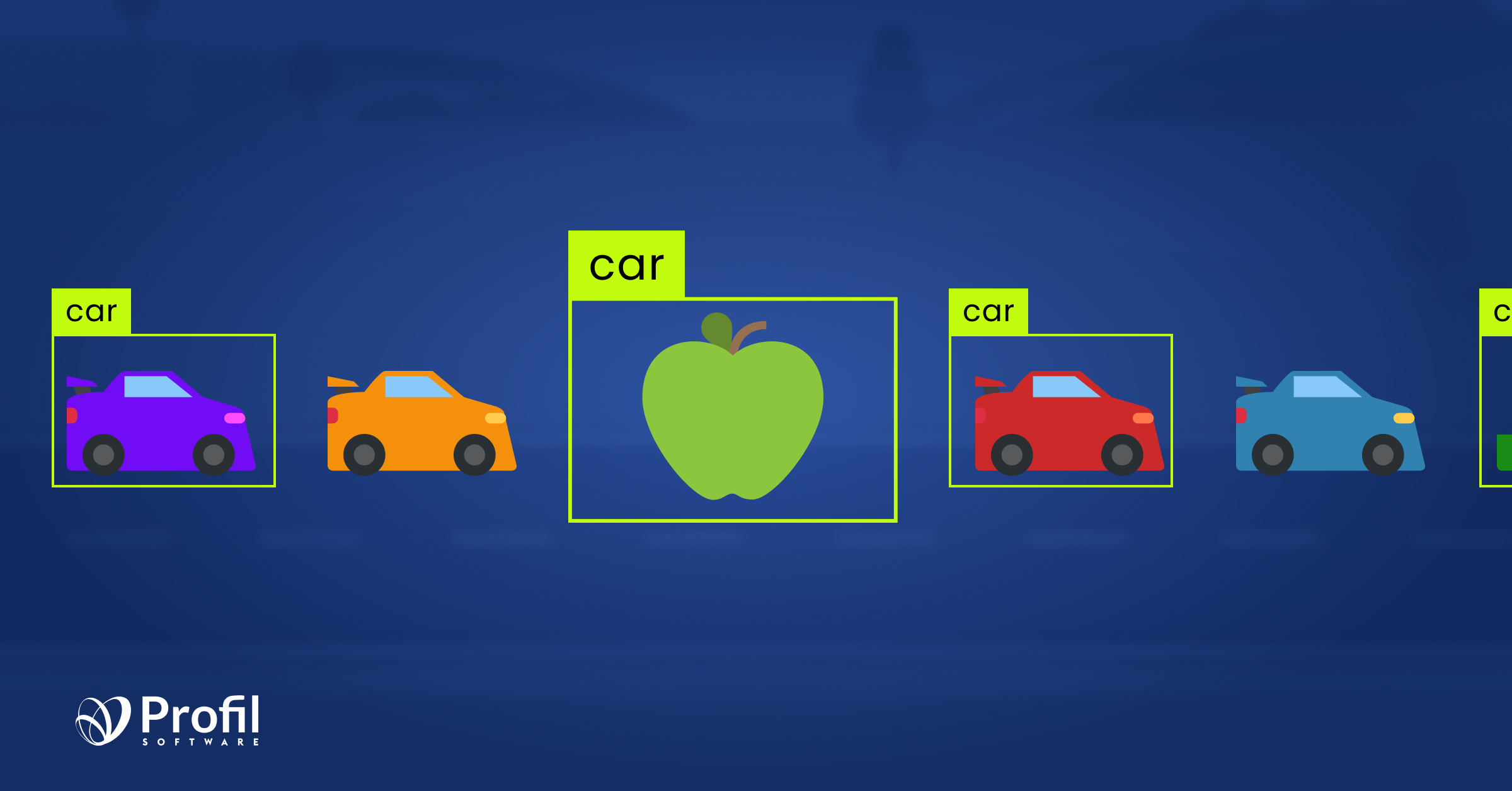
Image classification
Image classification refers to a process in computer vision that can classify an image according to its visual content. It should not be mistaken with other similar operations such as localization, object detection or segmentation. The below image shows the difference to make sure that everything is clear:
Experiments' description
Before going through with our experiment, let's have a look at what an adversarial attack is. Adversarial attacks are a subtle modification of an original image. It is done in a way that makes the changes almost unnoticeable for the eye. The modified image is called an adversarial image, and if you submit it to a classifier it will be misclassified, whereas the original one will be the one correctly classified. To sum up, successful adversarial examples are the ones that has been modified but the change is not detectable for human eye.
For the purpose of this article I've chosen two algorithms to go through. The first one is a genetic algorithm used for One Pixel Attack which, as its name suggests, changes only a single pixel value to fool the classification model. The second one is FGSM attack (Fast Gradient Sign Method) which modifies an image with a little noise that is practically unseen by humans but can manipulate the model's prediction.
One Pixel Attack
When I was searching the net to find ways to fool Deep Neural Network model (DNN), I ran across the very interesting concept of One Pixel Attack, and I knew I needed to check it out. My intuition was telling me that changing only one pixel in the original input image wouldn't be enough to break all those concepts of filters and convolutional layers used in neural networks that do a great job when it comes to object classification.
The only information that was used to manipulate the input image was the probability of classification (percentage values for each label). I wanted to achieve that without a brute force method by using GA (Genetic Algorithm). The idea was easy:
- Get the true label for a given image.
- Draw a base population of changed pixels (encoded as xyrgb), where x and y is the position of a pixel and r, g and b are its color components.
- Do GA magic (crossing, mutation, selection) taking into account the population diversity.
- End calculations when the probability decreases under 20% or after a certain number of steps without appreciable results.
For the experiments I used a model based on the VGG16 architecture for the cifar10 dataset with pretrained weights (https://github.com/geifmany/cifar-vgg). It was done like this to eliminate the impact from a ‘potentially' badly trained model. The sample code below is presented to get a kick-start with training your own models on that dataset:
The results obtained from the attack were really good because for almost 20% of the images, changing only one pixel successfully led to misclassification.
The results obtained from the attack were really good because for almost 20% of the images, changing only one pixel successfully led to misclassification.
Fast Gradient Method (FGSM attack)
Another method I found is FGSM (Fast Gradient Sign Method), which is extremely easy in its concepts, but also leads to great effects. Without getting too deep into all the technical issues, this method is based on calculating the gradient (between input and output of neural net) for a given image that will increase the classification of the true label.
For an untargeted approach the next step is just to add the sign value of the gradient (-1, 0 or 1 for each pixel component) to an image to avoid a good prediction. Some studies also use a param called epsilon , a multiplier for the sign value, but in this experiment we considered images represented by integer rgb values. This step can be repeated a few times to get satisfying results.
Another approach is a targeted attack which differs in the way the gradient is calculated. For this type of attack it is taken between the original input image and target label (not true label). It is then subtracted from image to move the classification closer to the aim. Easy isn't it? I've pasted some sample code below to make it easier to understand.
The model that was used in this experiment is resnet18 with imagenet weights. The sample code that enables its loading (using image-classifiers==0.2.2) is pasted below:
The below image presents original and adversarial example generated using FGSM + generated noise after 2 steps of the algorithm:
The model that was used in this experiment is resnet18 with imagenet weights. The sample code that enables its loading (using image-classifiers==0.2.2) is pasted below:
The below image presents an original and adversarial example generated using FGSM + generated noise after 2 steps of the algorithm:
The model that was used in this experiment is resnet18 with imagenet weights. The sample code that enables its loading (using image-classifiers==0.2.2) is pasted below:
Black-box FGSM
As you probably know, a white box attack means that we know everything about the deployed model, for example, inputs, model architecture, and specific model internals like weights or coefficients, but a black box attack is when we only know the model's inputs and have the possibility of observing their outputs.
The previous method was an easy case where we had full info about the attacked model, but what happens when it is not available ? Here is a study that estimates the gradient by using a large amount of queries to the target model. I tried to fool the target model using my own model that had a different architecture but did similar tasks.
The modified images were prepared based on my model (it took 7 steps to decrease true label prediction under 1%) and checked by the target model (vgg16 cifar10 model used in previous steps). Results from this experiment are shown below:
These results look promising but we have to take into account that these are relatively simple tasks (classifying 32x32 pixel images), and the difficulty of fooling other models will probably grow with the complexity of the structures that are used.
Conclusion
The approaches that were presented show that we can perturb images in a way to manipulate classification results. This is easy when we have full info about model structure. Otherwise it is hard to estimate perturbed samples with limited access to the target model.
The knowledge that comes from these experiments can help to defend from such attacks by extending the training set with slightly modified images.
For more interesting software development subjects you can visit our software development blog, and if you're a fan of machine learning, deep learning and artificial intelligence, I wrote an article on Sentiment analysis on Twitter posts that you can read next.
Resources
- https://arxiv.org/pdf/1710.08864.pdf
- https://arxiv.org/pdf/1712.07107.pdf
- https://github.com/geifmany/cifar-vgg
- https://arxiv.org/pdf/1904.05181.pdf
published at
ResearchGate: Tricking Neural Networks
Dev.to: Tricking Neural Networks
Thanks to Peter Plesa.
Got an idea and want to launch your product to the market?
Get in touch with our experts.
Przemysław PrzybytWhat are neural networks used for?
Neural networks aid computers in making intelligent decisions with little assistance from a human being. They learn and model the relationships between nonlinear and complex input and output data.What are the 3 most popular types of neural networks?
Multi-Layer Perceptrons (MLP) Convolutional Neural Networks (CNN) and Recurrent Neural Networks (RNN) are the three types of neural networks that are used the most.What is FGSM attack?
The Fast Gradient Sign Method (FGSM) is believed to be a simple but at the same time effective method to generate adversarial images.What does it mean to have a successful adversarial examples?
Adversarial examples are inputs created in order to confuse neural network, which is supposed to result in the misclassification of a given input. Simply, if misclassification is successful, the adversarial example is successful.