Table of Content
In today’s rapidly evolving technological landscape, AI models capable of generating human-like text, expansive language models, deep learning algorithms, and a plethora of AI solutions have become ever-present. These innovations continually permeate our software systems, facilitating efficiency and convenience in our daily lives.
Across diverse industries, the integration of machine learning algorithms and generative AI with language modelling approach has revolutionised operations, streamlining tasks and minimising time consumption. Amidst this burgeoning adoption, the demand for accelerated development of novel AI solutions is evident.
Machine learning models can be used for various tasks, including speech recognition, helping prevent predictions of low-probability (e.g. nonsense sequences), machine translation, natural language generation (i.e. generating text based on human language), optical character recognition, handwriting recognition, grammar induction, and more.
What is RAG?
Artificial Intelligence continues to grow and evolve, and it’s our responsibility to ensure that it can understand and interact with vast amounts of information. Retrieval Augmented Generation (RAG) is a groundbreaking innovation that represents a paradigm shift in AI Development. But what exactly is RAG?
RAG is an AI framework that combines two powerful techniques: retrieval and generation. Traditional AI models rely solely on generating responses based on a fixed dataset, but RAG takes this a step further. It integrates retrieval mechanisms, enabling AI to access and incorporate information from an extensive array of external sources. In short, RAG gives AI the ability to comprehend and respond to queries within a much broader contextual landscape.
The unique abilities of RAG make it a promising tool with the potential to revolutionize various domains. From customer service chatbots to data analysis tools, RAG can open doors to unprecedented levels of AI sophistication and capability.
Understanding RAG
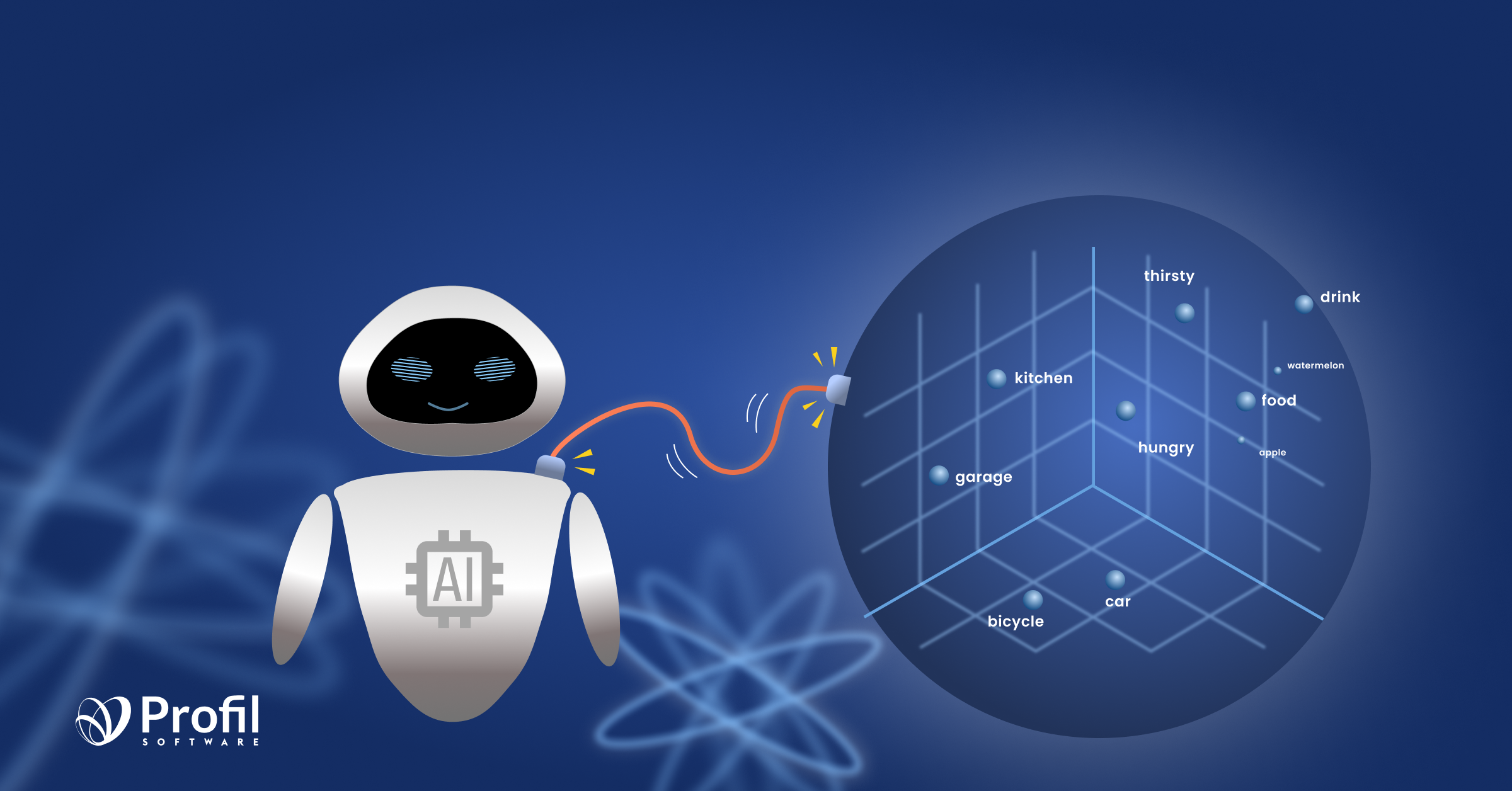
At its core, RAG relies on powerful language models, such as transformer-based architectures like GPT (Generative Pre-trained Transformer), to process and generate text. These models are pre-trained on vast amounts of text data to understand language patterns and semantic meanings. When a query is inputted into the system, RAG employs an embedding model to convert words or phrases into numerical representations, known as vectors.
Note: The most important thing to understand is that a vector represents the meaning of the input text, the same way another human would understand the meaning if you spoke the text aloud. We convert our data to vectors so that computers can search for semantically similar items based on the numerical representation of the stored data.

RAG leverages a retrieval mechanism to access a repository of documents or knowledge sources relevant to the query. This retrieval process involves indexing and organising the documents based on their semantic similarities to the query. We will talk later about semantic search.
Once the documents are retrieved, it’s like having the raw data retrieved from a database. But raw data isn’t always useful or easy to understand. That’s where the generator comes in.
With the context-rich documents at hand, RAG then employs its generative capabilities to synthesise a response or output that effectively addresses the query. By leveraging the contextual information extracted from the retrieved documents, the model can produce more accurate, informative, and contextually relevant responses compared to traditional generation approaches.
In summary, RAG operates by combining advanced language models with retrieval mechanisms to harness the power of context in generating insightful and relevant responses to queries. Through a nuanced interplay of embeddings, vectors, and document retrieval, RAG revolutionises the way AI systems understand and interact with information, paving the way for more intelligent and contextually aware applications.
Semantic search
In the realm of information retrieval, two prominent approaches emerge: lexical search and semantic search.
Lexical search operates based on matching keywords or phrases directly, retrieving documents that contain the exact terms inputted by the user. This approach mirrors the conventional search experience commonly encountered in everyday usage, where search bars and engines rely on keyword matching to fetch relevant results. While straightforward, lexical search may yield results that lack precision, as it doesn’t consider the contextual meaning or relationships between words.
On the other hand, semantic search employs advanced algorithms to understand the intent behind the query and the context in which it’s used. By analysing semantics, semantic search retrieves documents that are conceptually related to the query, even if they don’t contain the exact keywords. While lexical search remains effective for simple queries, Semantic search shines in complex scenarios where context plays a crucial role.
For example: If a user searches for “healthy recipes” a lexical search engine returns results that specifically contain the words “healthy” and “recipes.”
Semantic search focuses on understanding the meaning of the query and the context of the information rather than just matching keywords. If a user searches for “healthy recipes” a semantic search engine might also include recipes that use terms like “nutritious meals” or “wholesome cooking.”
Use cases
Some key use cases where RAG is particularly effective and should be highlighted:
- Content recommendation systems — RAG-powered recommendation engines deliver personalised content suggestions based on user preferences and wide product information data. This boosts user engagement and drives conversions, leading to increased revenue and customer satisfaction
- Conversational agents and chatbots — In customer service, RAG can empower chatbots to give more accurate and contextually appropriate responses. By accessing up-to-date product information or customer data, these chatbots can provide better assistance, improving customer satisfaction.
- Business intelligence and analysis: Businesses can use RAG to generate market analysis reports or insights by retrieving and incorporating the latest market data and trends.
- Healthcare information systems: In healthcare, RAG can improve systems that provide medical information or advice. By accessing the latest medical research and guidelines, such systems can offer safer and more accurate medical recommendations. Healthcare chatbots using RAG provide patients with health condition information, medication advice, doctor and hospital finding services, appointment scheduling, and prescription refills.
- Legal research: Legal professionals can use RAG to quickly pull relevant case laws, statutes, or legal writings, streamlining the research process and ensuring more comprehensive legal analysis. Chatbots using RAG can assist lawyers in finding case law, statutes, and regulations from various sources, providing summaries, answering legal queries, and identifying potential legal issues.
- Educational tools: RAG can be used in educational platforms to provide students with detailed explanations and contextually relevant examples, drawing from a vast range of educational materials.
- Civic tech: RAG can revolutionize how public services are delivered by powering intelligent search platforms for government and civic organizations. These systems enable citizens to access public records, legal texts, or municipal data with natural language queries, providing accurate and contextually relevant results. RAG can also assist in automating processes such as document categorization, data extraction, and knowledge base creation, improving transparency, efficiency, and accessibility in public services.
Example — building simple RAG with Python
In this simple example, we’ll craft a Python script showcasing some key features of RAG, leveraging the LangChain framework and ChromaDB as our vector storage.
Let’s load some example data into our Chroma instance:
Now our data is uploaded to the vector database and we can do a similarity search:
As we can see, the vector store returned the proper information that can now be used as context for our LLM model. Llet’s use the GPT model to generate a prettier response for the user.
Perfect! As we can see, RAG can eliminate hallucinations in large language models by incorporating retrieval mechanisms that provide contextual grounding for generated outputs.
This simple example shows how easily we can integrate our business data with large language models. Natural language processing models keep transforming our reality and we are responsible for learning the most we can about them and shaping them in a way that responds to the user needs. By fostering responsible development and utilization of AI, we can harness its full potential to empower individuals and societies, ensuring a future where technology catalyzes positive change.
Suggested blog posts
Find something interesting to read about
machine learningPrzemysław Przybyt